In a media streaming service, it is not recommended to stream one large media file, this slows down the user experience, also not all media formats are ideal for streaming. In this tutorial we will see the procedure to convert media to a format which is fit for streaming.
As the topic says we will see how we can create a media conversion pipeline using AWS services. We will make use of AWS Transcoder, Lambda function and S3 buckets in this process. In our case the input media will be in .MP4 format and the converted media will be in HTTP Live Streaming(HLS) with .M3U8 playlist. During the process of conversion our input media will be split in videos of 10secs sequences which results in faster streaming and better user experience.
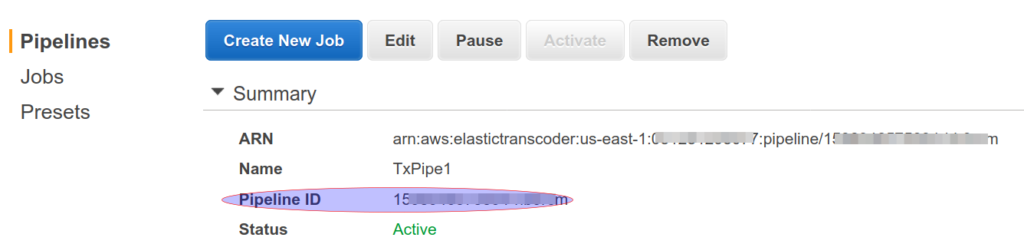
We will start with creating 2 S3 buckets, lets name them inputbucket and outputbucket. Next we create a Transcoder pipeline. Most of the field here are self explaining. Give your pipeline a name, select our inputbucket, let AWS Create console default role for IAM Role. Select the outputbucket and Standard Storage Class for transcoded files and playlists. You can use same outputbucket and Standard Storage Class for thumbnails. We do not need any notifications and keep the encryption as default. Once the pipeline is created note the pipeline id, see image below
We also need to know the Preset id for our output media format. Since we are going to use the HLS 2M we can get the id as below.

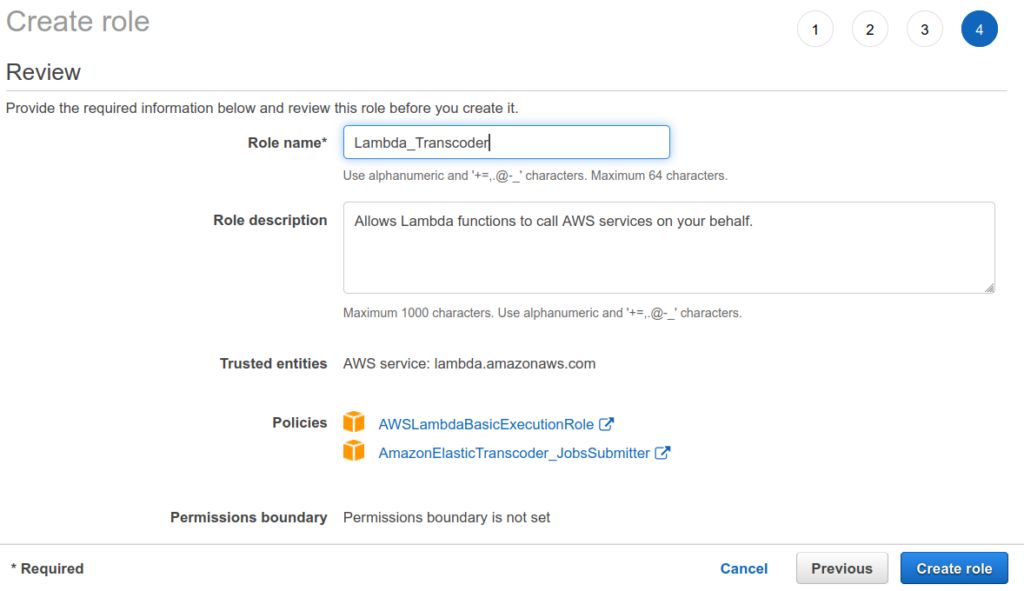
Before we setup our lambda function we need to create a new IAM role and attach the AmazonElasticTranscoder_JobsSubmitter and AWSLambdaBasicExecutionRole policies to it.
To do this go to Identity and Access Management → Roles → Create Role → Select AWS Services for Trusted Entity → Use case Lambda and attach the AmazonElasticTranscoder_JobsSubmitter and AWSLambdaBasicExecutionRole policies to it.
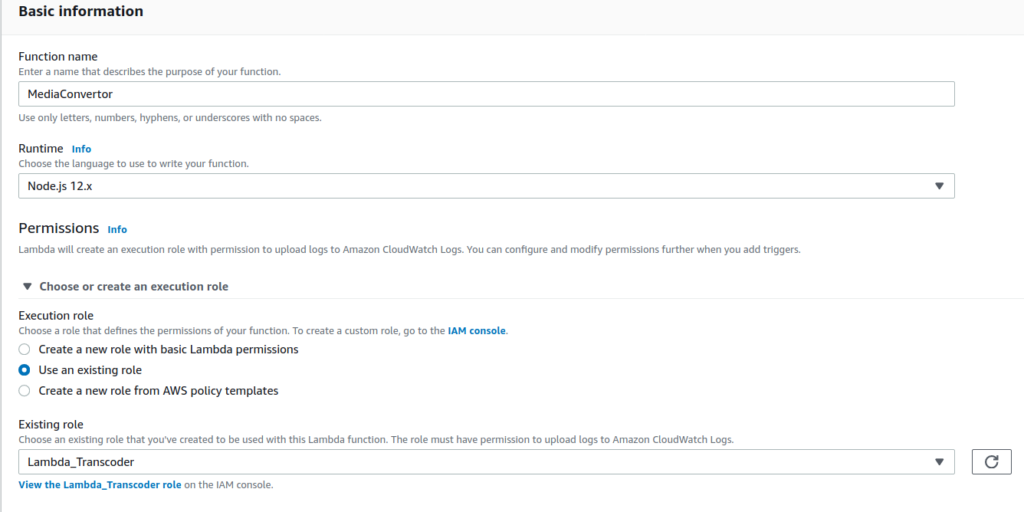
Now lets create the Lambda function from scratch which will be triggered wheneve a new media file is uploaded/created in the inputbucket, processes it through the transcoder pipeline and finally put the converted media to the outputbucket. We will use Nodejs as our runtime language and use the new role that we created in the previous step.
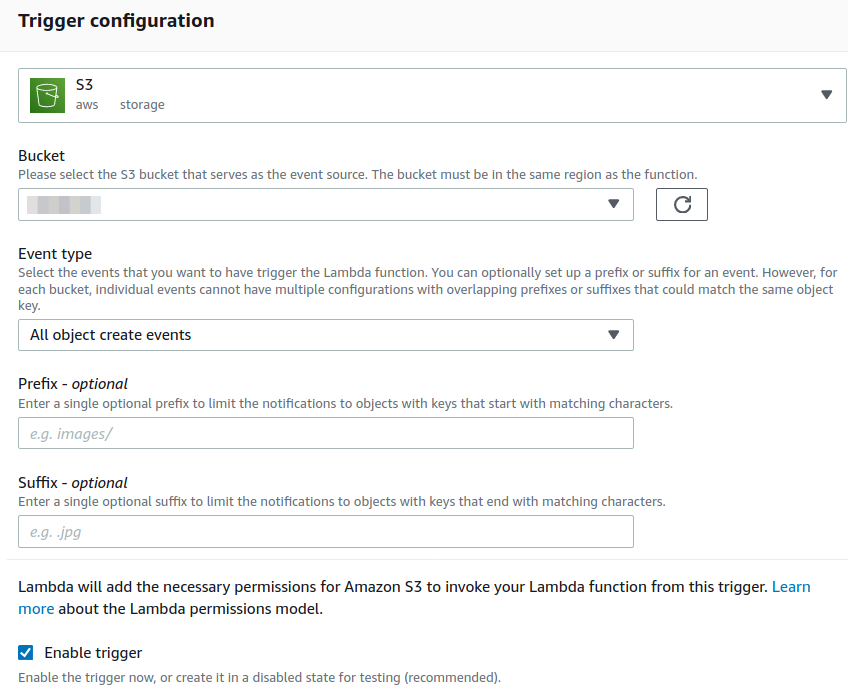
Next we setup a trigger for all create object events on our S3 inputbucket.
Below is the function code.
'use strict';
var AWS = require('aws-sdk');
var s3 = new AWS.S3({
apiVersion: '2012-09-25'
});
var eltr = new AWS.ElasticTranscoder({
apiVersion: '2012-09-25',
region: 'ap-south-1'
});
exports.handler = function(event, context) {
console.log('Executing Elastic Transcoder Pipeline');
var bucket = event.Records[0].s3.bucket.name;
var key = event.Records[0].s3.object.key;
var pipelineId = 'YOURPIPELINEIDHERE';
console.log(key);
console.log(event.Records[0]);
if (bucket !== 'inputbox') {
context.fail('Incorrect Video Input Bucket');
return;
}
var srcKey = decodeURIComponent(event.Records[0].s3.object.key.replace(/\+/g, " ")); //the object may have spaces
var newplusKey = key.split('.')[0];
var newKey = newplusKey.replace(/\+/g, '');
var params = {
PipelineId: pipelineId,
OutputKeyPrefix:'stream/',
Input: {
Key: srcKey,
FrameRate: 'auto',
Resolution: 'auto',
AspectRatio: 'auto',
Interlaced: 'auto',
Container: 'auto'
},
Outputs: [
{
Key: 'stream/'+newKey,
ThumbnailPattern: '',
PresetId: 'YOURPRESETIDHERE', //HLS 2M
SegmentDuration: '10'
}
],
Playlists: [
{
Name: newKey,
Format: 'HLSv3',
OutputKeys: [
'stream/'+newKey
],
},
]
};
console.log('Starting Job');
eltr.createJob(params, function(err, data){
if (err){
console.log(err);
} else {
console.log(data);
}
context.succeed('Job well done');
});
};
We are ready to use the pipeline, upload a new media file in inputbucket and in few seconds you will see converted medias with .ts and .m3u8 extensions in outputbucket. If anything goes wrong check the cloudwatch logs to troubleshoot.
Additionally you may want to allocate more memory and execution time to your lambda function, this can be done in the basic settings section.
We now have a fully working pipeline, ready to use 🙂